「ワークフロー」とは
ワークフローとは、一連の処理の流れを定義したものであり、データは異なるが同じような処理を繰り返し行う場合等に非常に有効な枠組みのことです。
例えば、単純なワークフローとして、あるアミノ酸配列があり、その配列と相同な配列を探し、それら相同な配列をもとに系統樹を作成する等があります。この場合、アミノ酸配列をBLAST等の探索プログラム等にかけ、その結果からいくつかの相同な配列を取り出し、ひとつのファイルにまとめて、系統樹を作成するプログラムもしくはサーバ等に渡し計算させ結果を得ます。
このとき、この作業を一度ひとつのワークフローとして定義しておけば(このワークフローを行うプログラムを定義または作成する)、繰り返し行う場合非常に効率的です。
典型的な作業の流れ
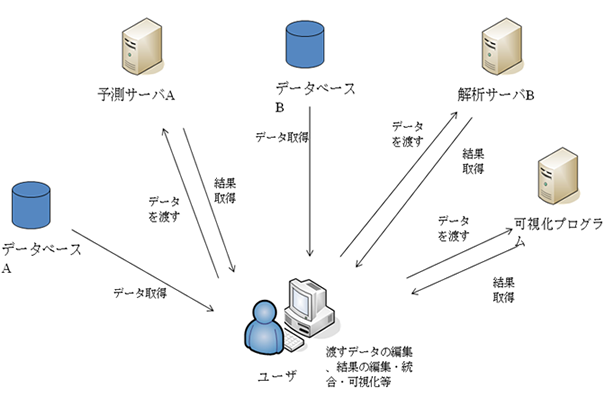
ワークフローにすると
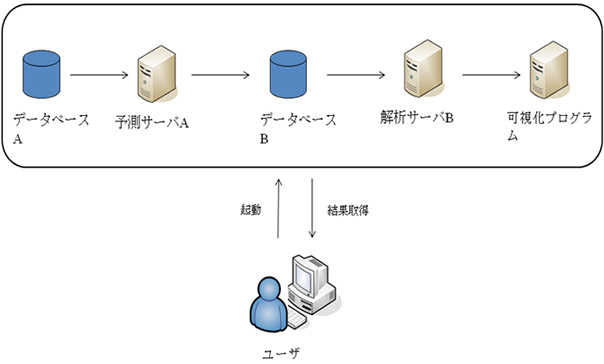
ワークフローは、固定型と可変型(ユーザ定義型)に大別されます。 固定型は予め定義された一連の処理を組み合わせており、ユーザは許された範囲内でのみパラメータ等の指定が可能であり、実行そのものは容易である半面、ユーザの自由にならない等の柔軟性に欠けます。他方、可変型はユーザが処理の組み合わせを指定することが可能であり、柔軟性は高いです。但し可変型は、固定型に比べ組み込む処理自由度を高まる必要から開発期間・コストの負担が大きいこと、またワークフロー構築に慣れるまで比較的時間がかかる等の課題もあります。
1.可変型ワークフロープラットフォーム例 KNIME
ビジュアルに容易にワークフローの構築が可能です。ワークフローの構成単位であるノード(コンポーネント)にユーザが必要とするものがない場合、作成する必要がありますが、作成難度は比較的高い傾向があります。
KNIMEサイト http://www.knime.org
2.可変型ワークフロープラットフォーム例 TAVERNA
上記KNIMEとほぼ同様で、予め用意されている構成部品が多い半面、若干難易度が高い傾向があります。
TAVERNAサイト http://taverana.sourceforge.net
「ワークフロー」と「分散処理」
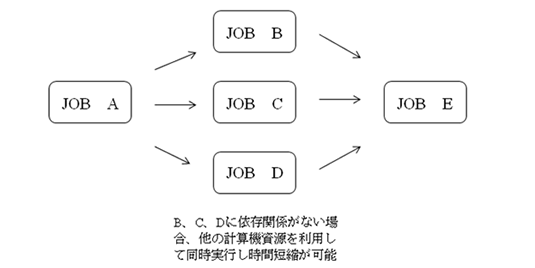
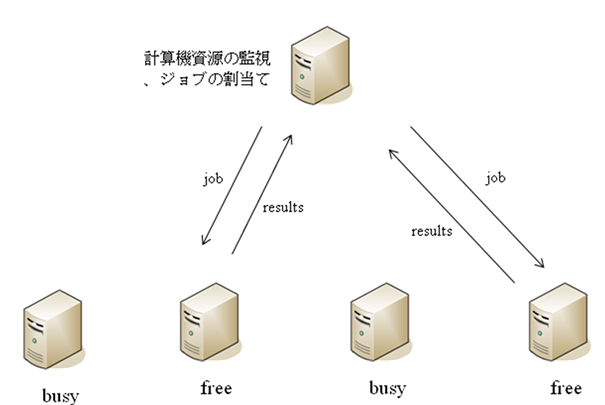
通常、ワークフローを実行する環境として、ユーザ自身のPC、遠隔サーバ上、両者混在などの形態があります。重要なことはユーザがそれらを意識する必要がないことであり、またどのように実行されようと迅速に処理が終了することです。ワークフローの中で全てのジョブに依存関係(次のジョブはその前のジョブの結果を使用する等)がある場合、一部のジョブの同時実行は困難ですが、依存関係がないジョブでは他の計算機資源を利用し同時実行することで全体の処理時間の短縮が可能となります。またこの並列・分散処理及び計算可能な計算機の探索・割当てもユーザが意識することなく行われることで利便性が向上します。
逐次処理

並列・分散処理
ワークフローにおけるジョブの分散・自動割り当て
「対話型Webサーバ」と「非対話型Webサービス」
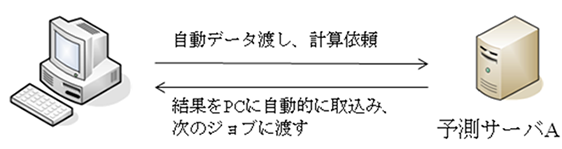
ワークフロー及び分散処理を実現するために必要な要素として、WEBサーバ(サービス)の提供形態が挙げられる。通常、解析・予測サービスは、ブラウザーから手動で配列を入力、パラメータを指定し、サーバ上で計算後結果をブラウザーで見るものが多い。これはユーザがブラウザーを使用してやりとりするとの前提であり、プログラムでのアクセスを想定していない。従ってそのままではプログラムでのデータのやり取りは困難な場合が多く、SOAP等のWEBサービス対応が必要となります。例えばSOAPとはデータのやり取りを規定するプロトコルのことで、SOAP対応している場合、ブラウザーを介さずデータのやりとりが可能となり、ワークフローに組み込むこともできます。従って、今後、有用なワークフロー構築には、サーバのSOAP対応等の増加が望まれます。
ブラウザーを介した利用

人手を介さない利用
「ワークフロー」技術開発について
従来、ソフトウェアやデータベースごとにアクセスし手間と時間がかかっていた一連の処理をまとめ、自動的に分散し短時間に効率よく行うワークフローを開発します。まずタンパク質の構造解析支援のワークフローを手始めに、利便性が高く、有用なものを目指して開発しました。
以下のタイプのワークフローを開発しています。
WEBベースワークフロー
ブラウザー経由でWEBサーバにアクセス、入力し計算終了後結果をブラウザーで見ます。
Activeワークフロー(ユーザ定義型ワークフロー)
ユーザのPC又はサーバにて、ワークフロープラットフォームを使用し、ユーザが望むワークフローを実行します。ユーザは様々な設定(実行部品の指定、パラメータ等)を指定することが可能です。